autoconfig
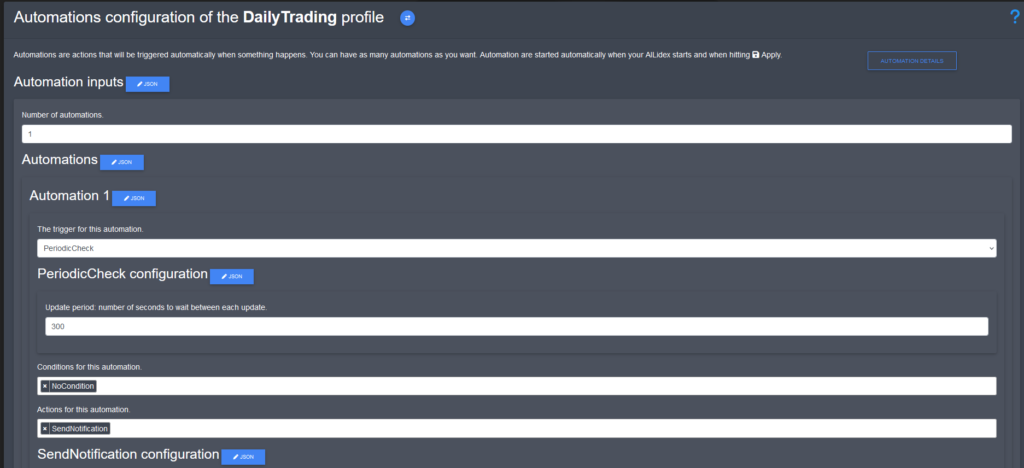
AILidex AutoConfig is a tool for AILidex settings automations. With AutoConfig, you can create “jobs” to automate tasks that you would typically do by hand, such as changing a profit target or scanning an exchange for potential pairs to add.
The tool enables you to schedule jobs in a cron-like system, providing you with complete flexibility and control over your automation. Jobs are defined as JSON objects. Simple jobs can be generated using the browser interface, use a code editor for complex jobs.
With AutoConfig, you can achieve a wide range of automation scenarios. Here are some examples of what you can do:
Scan exchanges and automatically add pairs: You can configure AutoConfig to add pairs based on specific criteria,such as volume, price, and trailing stops. You can also apply custom filters to ensure that only relevant pairsare added.
Create rules for pair removal: You can remove pairs that no longer meet your criteria, such as those with low volume or volatility.
Change the strategy for active pairs: You can set up custom strategies for handling specific pairs, such as bag handling strategies when prices drop.
Monitor pair state information and automatically set pair overrides: You can set up custom overrides for pairs based on their state information, such as setting a different gain target during an uptrend.
Orchestrate complex trading setups: You can use JavaScript to define custom autoconfig filters or rule based settings values. Variables can be stored on global or pair level. This allows for completely custom scenarios.
AutoConfig makes it possible to do complex automations for your AILidex settings, without requiring programming knowledge – although you can also use custom JavaScript code. Create powerful automations that meet your unique trading needs.
In AutoConfig, all job configurations are contained in a single file named autoconfig.json. This file can hold multiple job configurations. Whenever AILidex restarts or the autoconfig.json file is modified, all jobs within the configuration are automatically scheduled. Previously scheduled jobs are removed to avoid any conflicts.
Running jobs
Running AutoConfig jobs is a straightforward process that requires two things:
Enabled jobs, each job has an option to enable or disable it
AutoConfig itself enabled, which can be done through the browser interface on the AutoConfig page.
Creating simple jobs without writing code
To create a straightforward AutoConfig job, such as modifying a single strategy parameter through pre-built filter options, you can utilize the browser interface’s editor. The editor will walk you through each necessary step, but before beginning the job configuration process, ensure that you have familiarized yourself with filters and job types by reading about them.
This editor allows for creating simple jobs
Creating more complex jobs
To create jobs with greater complexity, you can use the AILidex code editor. This tool is ideal for users comfortable with JSON, or for those with ambitious plans.
The editor offers autosuggest options for valid templates related to all job types and filters. However, if you prefer, you may use any editor you like, as the format for jobs is simply JSON.
The JSON based config is easier for more complex jobs. The editor has code suggestions for templates of valid jobs and filters.
General info about jobs
When a job is processed, changes to the config.js file are made only for pairs that pass all filters in a filter set.
You can include one or many jobs in the autoconfig.json file, each with its own schedule. A job applies to a single exchange, and can have one or multiple filters. Within a job, you can specify filters to determine which pairs it applies to.
If a job successfully completes, the changes are written to config.js and AILidex starts using the new settings. Most config changes, such as pair override changes, are applied without restarting the bot. If a job doesn’t cause any changes, for example, because it attempts to place already existing overrides, it won’t cause a AILidex restart.
You can set schedules per job in a format similar to how cron jobs are set. If you’re not familiar with the format, you can use a website like https://crontab-generator.org/ to generate it.
All configuration options are available in the browser interface. We suggest creating a config example using the interface, even if you prefer manually editing the config file. This way, you can ensure all necessary parameters are included.
TIP
To avoid unexpected configuration changes when using a very fast schedule, such as jobs that update your bot configuration every few seconds, it is important to refrain from making manual setting changes using the browser while AutoConfig jobs are running. Be sure to make this a habit to maintain consistency in your bot’s configuration.
In AutoConfig, all job configurations are contained in a single file named autoconfig.json. This file can hold multiple job configurations. Whenever AILidex restarts or the autoconfig.json file is modified, all jobs within the configuration are automatically scheduled. Previously scheduled jobs are removed to avoid any conflicts.
Running jobs
Running AutoConfig jobs is a straightforward process that requires two things:
Enabled jobs, each job has an option to enable or disable it
AutoConfig itself enabled, which can be done through the browser interface on the AutoConfig page.
Creating simple jobs without writing code
To create a straightforward AutoConfig job, such as modifying a single strategy parameter through pre-built filter options, you can utilize the browser interface’s editor. The editor will walk you through each necessary step, but before beginning the job configuration process, ensure that you have familiarized yourself with filters and job types by reading about them.
This editor allows for creating simple jobs
Creating more complex jobs
To create jobs with greater complexity, you can use the AILidex code editor. This tool is ideal for users comfortable with JSON, or for those with ambitious plans.
The editor offers auto suggest options for valid templates related to all job types and filters. However, if you prefer, you may use any editor you like, as the format for jobs is simply JSON.
The JSON based config is easier for more complex jobs. The editor has code suggestions for templates of valid jobs and filters.
General info about jobs
When a job is processed, changes to the config.js file are made only for pairs that pass all filters in a filter set.
You can include one or many jobs in the autoconfig.json file, each with its own schedule. A job applies to a single exchange, and can have one or multiple filters. Within a job, you can specify filters to determine which pairs it applies to.
If a job successfully completes, the changes are written to config.js and AILidex starts using the new settings. Most config changes, such as pair override changes, are applied without restarting the bot. If a job doesn’t cause any changes, for example, because it attempts to place already existing overrides, it won’t cause a AILidex restart.
You can set schedules per job in a format similar to how cron jobs are set. If you’re not familiar with the format, you can use a website like https://crontab-generator.org/ to generate it.
All configuration options are available in the browser interface. We suggest creating a config example using the interface, even if you prefer manually editing the config file. This way, you can ensure all necessary parameters are included.
AutoConfig Job Types
Each job type serves a unique purpose. For instance, if you want to add pairs, you can use the addPairs job type. If you need to modify settings for a running pair, you can use the manageOverrides job type. It is important to select the appropriate job type based on the specific task you need to perform.
AILidex provides different job types that grant access to various data points. Some job types are designed to scan markets for data related to trading pairs that AILidex is not currently processing. For this purpose, they use ticker data. Other job types are intended for use with pairs that are already running in AILidex. They utilize data that is already available internally and do not consume extra API usage.
TIP
The addPairs, removePairs2, and manageOverrides job types are the most commonly used. These job types enable you to create a comprehensive workflow for adding pairs, managing their settings, and ultimately removing them. In most cases, these job types will suffice for your automation needs.
Job types overview
Check out the table below for a list of job types. If a job type requests ticker data from the exchange, it’s marked as using external data. On the other hand, if a job type uses internal data, it will be faster to execute and consume no API usage. It’s best to choose a job type that uses internal data whenever possible for the task you want to automate.
Job types by data source
External data Internal data
addPairs changeDelay
backtesting changeStrategy2
changeStrategy manageBotSettings
collectData manageOverrides
manageOverrides2 removePairs2
removePairs
Job types by primary function
Job type Primary function
addPairs Add trading pairs to a specific exchange
backtesting Simulate an addPairs job using data collected with a collectData job
changeDelay Change exchange delay
changeStrategy
changeStrategy2 Change assigned trading strategy for pairs
collectData Collect tickers data for use in a backtesting job
manageBotSettings Change AILidex config.bot settings
manageOverrides
manageOverrides2 Changes overrides for pairs
removePairs
removePairs2 Remove active trading pairs
Details per job type
Each job type has a number of obligatory parameters, these are described below for each job type. Additionally, there are optional parameters you can use to extend the functionality of a job.
Adding pairs
Type name in config: addPairs
This job type uses ticker filters.
Job output: add trading pairs to a specific exchange.
Pair options:
include: included pairs (processed first). Any pair on the exchange that matches any of the includes, will be processed. In case you also use the exclude option, the resulting pairs after processing the includes is the starting point for processing excludes, which will remove items from this list of pairs.
Included items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be included. Input as comma separated list, does not accept spaces between items. Can not be empty.
exclude: excluded pairs (processed last). Any pair on the exchange that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
maxPairs: maximum number of allowed pairs. In case a filter action would result in more pairs than this setting, the config will be filled up to the max number of allowed pairs. Only enabled pairs count towards maxPairs.
Other obligatory parameters:
strategy: this defines the strategy that will be assigned to pairs added by this job. It must be the exact name of an existing strategy in your config.js file.
snapshots: defines how many ticker snapshots are saved to perform calculations on. Relevant for filter types that include Interval in their name.
For example: snapshots is set to 10, this means that the ticker data for the last 10 times the job runs are saved and some of the values in it are used for calculating average values over time.
Config example
The example below shows a job that does the following:
Scan Binance tickers every minute
Automatically add BTC-x pairs (but not BTC-DOGE, which is excluded) that have a top 10 volume ranking and for which the bid/ask spread is below 0.2%
Added pairs get the “gain” strategy assigned
Allows for up to 25 active trading pairs on Binance
{
“addTopVolumePairs”: {
“pairs”: {
“exclude”: “DOGE”,
“include”: “BTC-“,
“maxPairs”: 25,
“exchange”: “binance”
},
“filters”: {
“filter1”: {
“type”: “maxVolumeRank”,
“max”: 11
},
“filter2”: {
“type”: “maxSpreadPct”,
“max”: 0.2
}
},
“schedule”: “* * * * *”,
“snapshots”: 1,
“type”: “addPairs”,
“strategy”: “gain”
}
}
Removing pairs
Type names in config: removePairs (uses ticker filters) or removePairs2 (uses state filters).
You must have at least one pair set per exchange you use this job type on.
Job output: removes trading pairs from a specific exchange.
Pair options:
exclude: pairs that should not be scanned for possible removal. Any active pair that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
There is no include options for this filter type. Pairs in your config (that have already cycled in AILidex) are basically the list of includes.
noBag (true/false): when true, only pairs with a balance below MIN_VOLUME_TO_SELL that have no open orders and are not in reversal trading, are filtered for possible removal. When set to false, all pairs in config are filtered.
removeDisabled (true/false): when true, each time a removePairs job is ran it will remove all disabled pairs for the exchange the job runs on – regardless of filter settings. Useful, for example, when you use COUNT_SELL.
Other obligatory parameters:
snapshots: defines how many ticker snapshots are saved to perform calculations on. Relevant for filter types that include Interval in their name.
For example: snapshots is set to 10, this means that the ticker data for the last 10 times the job runs are saved and some of the values in it are used for calculating average values over time.
Config example
The example below shows a job that does the following:
Scan Binance tickers every ten minutes
Remove any pair that has has a volume ranking below 20, besides pairs containing BNB or XVG in their name.
Additionally, remove all disabled pairs from the config.
{
“removeCrap”: {
“pairs”: {
“exclude”: “BNB,XVG”,
“noBag”: false,
“removeDisabled”: true,
“exchange”: “binance”
},
“filters”: {
“filter1”: {
“type”: “minVolumeRank”,
“min”: 20
}
},
“schedule”: “*/10 * * * *”,
“snapshots”: 1,
“type”: “removePairs”
}
}
Change strategy
Type names in config: changeStrategy (uses ticker filters) or changeStrategy2 (uses state filters).
This job type is basically the same as how removePairs works, but this one changes a pairs strategy instead of removing the pair.
You must have at least one pair set per exchange you use this job type on.
Job output: change assigned trading strategy for pairs on one exchange.
Pair options:
exclude: pairs that should not be scanned for possible removal. Any active pair that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
There is no include options for this filter type. Pairs in your config (that have already cycled in AILidex) are basically the list of includes.
bag (true/false): when true, only pairs with a balance below MIN_VOLUME_TO_SELL that have no open orders and are not in reversal trading, are filtered for possible removal. When set to false, all pairs in config are filtered.
Other obligatory parameters:
strategy: the target strategy to set for pairs matching all filters.
snapshots: defines how many ticker snapshots are saved to perform calculations on. Relevant for filter types that include Interval in their name.
For example: snapshots is set to 10, this means that the ticker data for the last 10 times the job runs are saved and some of the values in it are used for calculating average values over time.
Config example
The example below shows a job that does the following:
Scan Binance tickers every 15 minutes
Change the assigned strategy for any pair that has below median trading volume, except BTC-LTC
Assign the strategy “baghandler” to these pairs
{
“changeStrat”: {
“pairs”: {
“exclude”: “BNB-LTC”,
“bag”: true,
“exchange”: “binance”
},
“filters”: {
“filter1”: {
“type”: “belowMedianVolume”
}
},
“schedule”: “*/15 * * * *”,
“snapshots”: 1,
“type”: “changeStrategy”,
“strategy”: “baghandler”
}
}
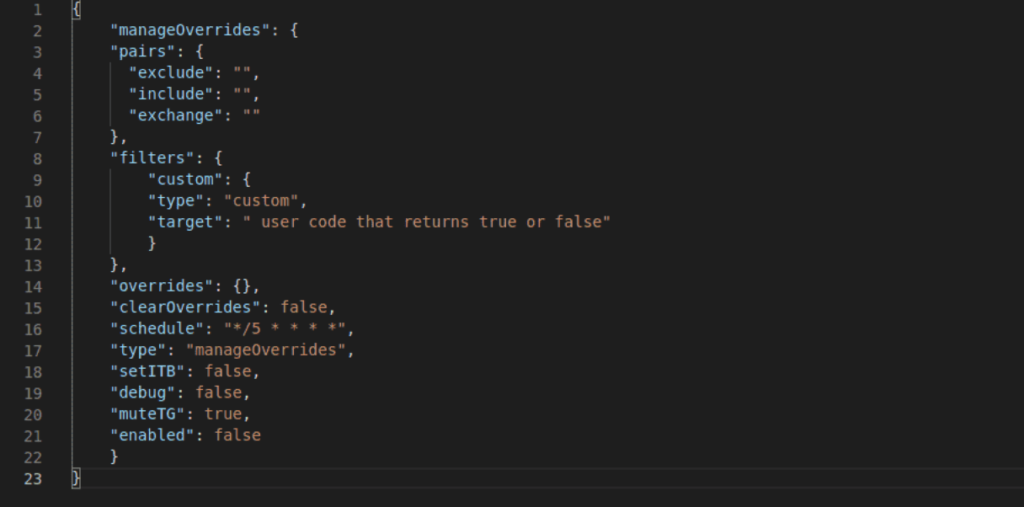
Managing overrides
Type name in config: manageOverrides
This job type uses state filters.
Job output: changes overrides for pairs on a specific exchange.
Pair options:
include: included pairs (processed first), can not be empty. Any active trading pair that matches any of the includes, will be processed. In case you also use the exclude option, the resulting pairs after processing the includes is the starting point for processing excludes, which will remove items from this list of pairs.
Included items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be included. Input as comma separated list, does not accept spaces between items. Can not be empty.
exclude: excluded pairs (processed last). Any active trading pair that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
Other obligatory parameters:
overrides: contain zero or more overrides, these will be set for each pair that passes all filters when a job is executed.
clearOverrides (true/false): when set to true, all existing overrides for a pair are removed before placing the new ones.
Config example
The example below shows a job that does the following:
Scan Binance pairs every minute, process filters on all active trading pairs that include “USDT” or “BNB” and do not include “DOGE” or “ETH” in their pair name.
Set a DU_BUYDOWN override for all pairs that have ducount 1
{
“DynamicDU1”: {
“pairs”: {
“exclude”: “DOGE,ETH”,
“include”: “USDT,BNB”,
“exchange”: “binance”
},
“filters”: {
“ducount”: {
“type”: “exact”,
“ducount”: 1
}
},
“overrides”: {
“DU_BUYDOWN”: 3
},
“clearOverrides”: false,
“schedule”: “* * * * *”,
“type”: “manageOverrides”
}
}
Change exchange delay
Type name in config: changeDelay
This job type uses state filters.
Job output: changes the exchange delay for a specific exchange.
Pair options:
include: included pairs (processed first), can not be empty. Any active trading pair that matches any of the includes, will be processed. In case you also use the exclude option, the resulting pairs after processing the includes is the starting point for processing excludes, which will remove items from this list of pairs.
Included items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be included. Input as comma separated list, does not accept spaces between items. Can not be empty.
exclude: excluded pairs (processed last). Any active trading pair that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
Other obligatory parameters:
delay: exchange delay in seconds, this value will be set when one or more pairs in the job pass all filters.
Config example
The example below shows a job that does the following:
Scan Binance pairs every minute, process filters on all active trading pairs that include “USDT” or “BNB” and do not include “DOGE” or “ETH” in their pair name.
Set a the exchange delay for Binance to 10 in case at least one pair matches the filter
{
“DynamicDU1”: {
“pairs”: {
“exclude”: “DOGE,ETH”,
“include”: “USDT,BNB”,
“exchange”: “binance”
},
“filters”: {
“ducount”: {
“type”: “exact”,
“ducount”: 1
}
},
“delay”: 10,
“schedule”: “* * * * *”,
“type”: “changeDelay”
}
}
Manage bot settings
Type names in config: manageBotSettings (uses state filters).
This job type is basically the same as how changeStrategy works, but this type is able to change the global bot settings.
You must have at least one pair set per exchange you use this job type on.
Job output: change assigned parameters in the bot section. Happens when at least one pair passes all filters
Pair options:
exclude: pairs that should not be filtered. Any active pair that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
There is no include options for this filter type. Pairs in your config (that have already cycled in AILidex) are basically the list of includes.
Other obligatory parameters:
bot: the target bot settings.
Config example
{
“botsettings”: {
“pairs”: {
“exclude”: “”,
“include”: “BTC-“,
“exchange”: “binance”
},
“filters”: {
“price”: {
“type”: “biggerThan”,
“Ask”: 0.00000001
}
},
“bot”: {
“BOT_DELAY”: 20,
“BOT_CCLEAN”: 9991
},
“schedule”: “* * * * *”,
“type”: “manageBotSettings”
}
}
Hedge (for AILidex)
Type names in config: hedgeGB (uses ticker filters) or hedgeGB2 (uses state filters).
You must have at least one pair set per exchange you use this job type on.
Job output:
You can define a “hedge pair” like USDT-BTC, between which AILidex should hedge when the market conditions are right for it. If you prefer hedging between completely other currrencies, like BTC-ETH – you can do that too.
It works with two autoconfig jobs, in which you define when it should hedge and to which currency it should hedge.
When a pair can be hedged without intermediate pair, autoconfig will change a pair like BTC-ETH to USDT-ETH and panic sell directly to ETH.
When an intermediate pair is needed, the pair will be panic sold first and then traded on the defined hedge pair.
Pair options:
Pair filtering is hardcoded to the defined hedge pair.
exclude: used as placeholder
bag: used as placeholder
baseFrom: base currency to hedge away from
baseTo: base currency to hedge to
hedgePair: pair used for hedging, like USDT-BTC
Other obligatory parameters:
setVariable: hedging will only work when both hedging jobs set a variable with the currency it last hedged to, this makes sure that the direction can be tracked for the next hedging action.
Config example
You’ll need two jobs to do this, one for each hedging direction:
{
“hedging”: {
“pairs”: {
“exclude”: “”,
“exchange”: “binance”,
“bag”: false,
“baseFrom”: “BTC”,
“baseTo”: “USDT”,
“hedgePair”: “USDT-BTC”
},
“filters”: {
“filter1”: {
“type”: “yourTickerFilter”,
“min”: “0.0000000001”
},
“filter2”: {
“type”: “variableNotExist”,
“hegdedTo”: “BTC”
}
},
“filters2”: {
“filter1”: {
“type”: “yourTickerFilter”,
“min”: “0.0000000001”
},
“filter2”: {
“type”: “variableExact”,
“hegdedTo”: “BTC”
}
},
“setVariable”: {
“hegdedTo”: “USDT”
},
“strategy”: “gain”,
“schedule”: “1 */4 * * *”,
“type”: “hedgeGB”,
“debug”: false
}
}
The second job would be a mirror job, with all hedge currencies reversed.
Two important notes:
keep the hedge pair in your config at all times, prefably with buy/sell disabled to avoid crossover between base/quote.
set the filter for “type”: “variableNotExist”, ONLY in the job that will take care of the next hedging action. For example, when you start out with BTC-x pairs only, add this filter to the job that hedges to USDT.
Hedge (for bitRage)
Type name in config: hedge
This job type uses state filters.
Job output: initiates hedging in bitRage.
Pair options:
include: included pairs (processed first), can not be empty. Any active trading pair that matches any of the includes, will be processed. In case you also use the exclude option, the resulting pairs after processing the includes is the starting point for processing excludes, which will remove items from this list of pairs.
Included items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be included. Input as comma separated list, does not accept spaces between items. Can not be empty.
exclude: excluded pairs (processed last). Any active trading pair that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
Other obligatory parameters:
hedgeTo (USDT/BTC): defines which currency to start hedging to.
brStrat: defines which strategy is used for bitRage.
Config example
The example below shows a job that does the following:
Scan for a user variable, every minutes
Once this variable is found, it places filteredBase, filteredQuote and filteredPair blocks as defined in the job, for kucoin (this part is optional)
Once this variable is found, it makes the following changes in the strategy bitrageStrat, it sets/changes the following parameters so that hedging will start:
“AUTOSELL”: true,
“MAIN_BASE”: “USDT”,
“BR_PANIC_SELL”: true,
{
“Hedge_to_USDT”: {
“pairs”: {
“exclude”: “”,
“include”: “”,
“exchange”: “kucoin”,
“filteredBase”: [
“TUSD”,
“PAX”,
“KCS”,
“NUSD”,
“ETH”,
“DAI”,
“USDC”,
“TRX”,
“NEO”,
“BTC”
],
“filteredQuote”: [
“GGC”
],
“filteredPair”: [
“BTC-GGC”,
“USDT-GGC”,
“BTC-KCS”,
“USDT-KCS”,
“KCS-XRP”,
“KCS-EOS”,
“KCS-LTC”,
“KCS-NEO”,
“KCS-MTV”,
“KCS-GO”,
“KCS-CS”,
“ETH-KCS”,
“NEO-EOS”,
“DAI-BTC”,
“DAI-ETH”,
“DAI-MKR”,
“DAI-USDT”
]
},
“filters”: {
“variable”: {
“type”: “variableExact”,
“readyToHedge”: “USDT”
}
},
“setVariable”: {
“hedgingStarted”: true
},
“schedule”: “* * * * *”,
“type”: “hedge”,
“hedgeTo”: “USDT”,
“brStrat”: “bitrageStrat”
},
}
Filtered quote (for bitRage)
Type name in config: filteredQuote
This job type uses ticker filters.
Job output: It adds the quote of each pair passing all filters to the filteredQuote list. Each time the job runs, the list gets completely replaced with the new results.
Pair options:
include: included pairs (processed first). Any pair on the exchange that matches any of the includes, will be processed. In case you also use the exclude option, the resulting pairs after processing the includes is the starting point for processing excludes, which will remove items from this list of pairs.
Included items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be included. Input as comma separated list, does not accept spaces between items. Can not be empty.
exclude: excluded pairs (processed last). Any pair on the exchange that matches any of the excludes, won’t be processed.
Excluded items do not need to be whole pair names, as long as part of the string matches an actual pair, it will be excluded. Input as comma separated list, does not accept spaces between items. Can be empty.
Config example
The example below would do the following:
scan all binance BTC-x pairs
find pairs with a bid/ask spread higher than 0.7%
save the quote coins from these pairs in the filteredQuote list.
{
“filteredQuote”: {
“pairs”: {
“include”: “BTC-“,
“exclude”: “”,
“exchange”: “binance”
},
“filters”: {
“spread”: {
“type”: “minSpreadPct”,
“min”: 0.7
},
“schedule”: “* * * * *”,
“type”: “filteredQuote”,
“debug”: false
}
}
Optional parameters
Optional Parameter Possible Values Job Type(s) Description
enabled true/false All job types When false, the job is disabled and won’t be executed.
debug true/false All job types When true, the job generates detailed logs in the console for each filter.
settings for user variables – All job types Allows for configuration of user-defined variables.
brStrat – All job types (specifically for bitRage) Defines which strategy is used for bitRage. Only needed if you use Autoconfig to automate hedging for bitRage.
resume true/false Jobs using ticker filters When true, saved ticker snapshots are loaded from file after AILidex restarts. When false, history needs to be built up again after restarting.
history – Jobs using ticker filters Defines how many ticker entries should be kept in storage.
historyInterval – Jobs using ticker filters Defines the minimum interval in minutes between history entries.
setITB true/false addPairs and manageOverrides When true, each pair matching all filters will get an additional IGNORE_TRADES_BEFORE override, the value being the timestamp for the time the job ran. For manageOverrides only.
delay time in seconds manageOverrides When set, the exchange delay gets adjusted to the specified value when at least one pair passes all filters.
overrides – addPairs This job type can also add overrides when it adds new pairs. To do so, add a section with overrides to the job, just like you would in a manageOverrides job.
noCrossOver true/false addPairs (specifically for bitRage) When set, Autoconfig will never add two pairs with different Base but the same Quote currency.
removeBase – removePairs Can be used to remove all pairs from a specified base currency that use the bitRage strategy specified in brStrat. This is useful to clean out pairs from a specific base after hedging.
notRemoveBefore value in minutes removePairs Don’t remove pairs from config if it’s not in the config longer than specified.
Bitrage filters – hedge When used for Bitrage, you can have an addPairs job replace the contents of the exchange filter settings. To do so, add the filteredQuote, filteredPair and filteredBase filters in the pair section of the job.
Backtesting for addPairs jobs
Results for addPairs jobs can be simulated using ticker data you’ve collected yourself. Self-collection is needed because the type of historic data AutoConfig uses is not publicly available.
Before you can backtest, you need to collect a dataset with a “collectData” job. This is a simple autoconfig job that collects and saves ticker data according to the job schedule and exchange.
“30-secs”: {
“pairs”: {
“exchange”: “binance”
},
“schedule”: “*/30 * * * * *”,
“type”: “collectData”,
“snapshots”: 1000,
“enabled”: true,
“debug”: false
}
The schedule in this job should be the same as the schedule you’d use in an addPairs job. It will collect up to 5 ticker snapshots and removes older snapshots in case they exist.
You can use any number of snapshots in this job type. If you omit the snapshots parameter, it will collect ticker snapshots for as long as your system has free disk space.
Ticker data for this collection job is saved in /30-secs-tickers (#jobname#-tickers). Do make sure you never save any other files in this folder.
As long as the collectData job runs, it keeps collecting tickers. It is not recommended to permanently collect tickers while also running other autoconfig jobs that use tickers: API usage weight is relatively high, and it will slow down AILidex performance slightly.
To backtest using the collected data, run a job with type backtesting. Do this while you have AILidex core and other autoconfig jobs disabled, because it’s very cpu intensive and you don’t want other jobs to interrupt.
A backtesting job is basically the same as an addPairs job, you can use all available filter / filterset options. Collected ticker data is replayed as if it were live data, the results should 100% match the results from a regular addPairs job. Results are logged the same way as regular jobs, the debug option for jobs is also available. “History” ticker snapshots can be used as well, these are built up in RAM while running through a backtest.
Results are saved to a .csv file that lists when pairs would have been added, and what the ask price was at that moment.
Backtesting jobs also use the autoconfig scheduler, although it’s kind of pointless. It’s recommended to set a silly schedule that will almost never execute and use the “onStart”: true option so that the job runs as soon as it gets enabled.
Backtesting does not take maxPairs into consideration (and will not in the future), results are purely based on the filters you use.
Job example for backtesting:
“30-secs”: {
“pairs”: {
“exclude”: “”,
“include”: “BTC-“,
“exchange”: “binance”
},
“filters”: {
“slope”: {
“type”: “minSlopePctInterval”,
“min”: 0.02
},
“volume”: {
“type”: “minVolume24h”,
“min”: 75
},
“pricehistory0”: {
“type”: “maxPricePctChangeIntervalHistory”,
“max”: 5,
“historySource”: 9
}
},
“schedule”: “1 1 1 1 1”,
“type”: “backtesting”,
“tickersFolder”: “30-secs-tickers”,
“enabled”: true,
“onStart”: true,
“history”: 10,
“historyInterval”: 2,
“debug”: false,
“snapshots”: 10
}
The data source for backtesting is set with the “tickersFolder” parameter. Set it to the exact folder name where your collected ticker files are. i
Various
You can schedule multiple jobs for the same time, but if more than one job causes a configuration change, only the first to finish will apply its changes. The others must wait for another chance.
Each job updates the config.js file, which always triggers a AILidex restart.
If you need detailed console log output for your filters, you can add debug: true to your job. However, use this option sparingly because it can significantly slow down AILidex performance due to the large amount of data logged to the console.
AutoConfig may crash if you change the exchange for a ticker filtering job while using resume: true, or if you use a non-existent key in a state filter, among other things.
Pair state data for filtering is available from either exchange tickers or internal AILidex memory. You can find information about which pair state data to filter on in the pairs state file located in the AILidex /json folder.
If you don’t want Telegram notifications for a specific job, include muteTG: true in that job.
You can filter almost any key/value pair in pair state files as long as they’re on the first level and not inside additional arrays or objects. Use a custom filter if you need to access nested values.
AutoConfig Filter Types
AutoConfig jobs support various filter types. These include:
Type Usage
Ticker filters Used for jobs that require external data.
Pair state filters Used for jobs that require internal data.
Generic filters Used for all job types.
User Variables This is not a filter category category of, instead it is data that can be stored and retrieved from within any job.
User variables can be filtered, and accessed by other jobs than the one that saved them.
Ticker filters
Ticker filters request data from exchange tickers at the time the job runs. Different types of filters can be applied to add or remove pairs, but not all filter types work on every exchange due to varying availability of required data. For example, on Huobi AutoConfig, last price is used instead of bid/ask for all price-related filters.
The following table provides an overview of available filter types with their descriptions and any additional details.
Type Description Extras
minPrice Returns true if the price is higher than set. n/a
maxPrice Returns true if the price is lower than set. n/a
minPricePctChangeInterval Returns true if the current price is at least x% higher than the average price of all snapshots. lastSnapshots
maxPricePctChangeInterval Returns true if the current price is at least x% lower than the average price of all snapshots. lastSnapshots
minVolumePctChangeInterval Returns true if the current 24h volume is at least x% higher than the average 24h volume of all snapshots. lastSnapshots
maxVolumePctChangeInterval Returns true if the current 24h volume is at least x% lower than the average 24h volume of all snapshots. lastSnapshots
minVolume24h Returns true if the 24h volume is higher than set (volume in base). n/a
maxVolume24h Returns true if the 24h volume is lower than set (volume in base). n/a
minVolatilityPct24h Returns true if the 24h price percentage change is higher than set. n/a
maxVolatilityPct24h Returns true if the 24h price percentage change is lower than set. n/a
minSpreadPct Returns true if the percentage difference between bid and ask is higher than set. n/a
maxSpreadPct Returns true if the percentage difference between bid and ask is lower than set. n/a
minSlopePctInterval Returns true if the slope for all prices in snapshots is bigger than set. lastSnapshots
maxSlopePctInterval Returns true if the slope for all prices in snapshots is smaller than set (executed only when max snapshot sample size is reached). lastSnapshots
minStandardDevPctInterval Returns true if the standard deviation for all prices in snapshots is bigger than set (executed only when max snapshot sample size is reached). lastSnapshots
maxStandardDevPctInterval Returns true if the standard deviation for all prices in snapshots is smaller than set (executed only when max snapshot sample size is reached). lastSnapshots
minVolumeRank Returns true if a pair’s 24h volume rank (rankings are specific per base) is higher than set. n/a
maxVolumeRank Returns true if a pair’s 24h volume rank (rankings are specific per base) is lower than set. n/a
bullishStandardDeviationChannel Returns true if the price is within a defined range from the lower band and other conditions are met (detects downwards breakout from upwards channel). lastSnapshots
bearishStandardDeviationChannel Returns true if the price is within a defined range from the upper band and other conditions are met (detects upwards breakout from downwards channel). lastSnapshots
linearRegressionChannel Returns true if the price is within a defined range from the lower band and other conditions are met (same as “Linear regression” indicator on TradingView). lastSnapshots
TIP
If you collect 48 ticker snapshots and the job runs every five minutes, that means any *Interval job works with 4h of market data (48 x 5).
Note that some filters have additional parameters that must be set to function properly. The minPricePctChangeInterval and maxPricePctChangeInterval filters require the lastSnapshots parameter to calculate the average price of all snapshots.
The lastSnapshots input allows you to select a specific number of recent snapshots to use for calculating a filter. For instance, if your task generates 100 snapshots but you only want to use the last 10 snapshots to calculate slope for a particular filter, you can specify this using lastSnapshots.
Filter notation examples
“spread”: {
“type”: “minSpreadPct”,
“min”: 0.5
},
“volume”: {
“type”: “belowMedianVolume”
},
“stdev”: {
“type”: “maxStandardDevPctInterval”,
“max”: 0.3
},
“channel”: {
“type”: “bullishStandardDeviationChannel”,
“range”: -10
},
“maxStandardDevPctInterval”: {
“type”: “minVolumePctChangeInterval”,
“max”: 1,
“lastSnapshots”: 3
}
“hedge”: {
“type”: “allowsHedging”,
“BTC”: “USDT”
}
Trailing filters
Trailing filters are ticker filters that trail down prices or volume. There are three types of trailing filters: buyTrailing, volumeTrailing, and slopeTrailing. Buy trailing is similar to a regular AILidex strategy and can be used to add pairs to your configuration only after they have hit their trailing stop. This is useful for trailing massive numbers of pairs without the downsides of long cycling times.
Note that these filter types can only be used in addPairs jobs on exchanges that provide ask prices or volume in tickers, and only work when used in the first filter set of a job.
Here’s an example configuration for buy trailing:
Collect up to 60 ticker snapshots, adding a new snapshot every time the job runs (every minute).
Use the 60 collected bid prices for a pair to calculate an EMA.
Continuously trail down all pairs using a trailingRange of 1% of the ask price.
The filter passes when the ask prices cross over the trailing stop while being below buyLevel (which is a percentage below the EMA calculated by this filter).
Volume trailing works the same as buy trailing, but base volume is used where prices are used in buy trailing. Slope trailing works like buy trailing but trails the slope percentage of a pair. Buy level is based on the same EMA as it is for buy trailing.
{
“trailingExample”: {
“pairs”: {
“exclude”: “”,
“include”: “BTC-,USDT-“,
“maxPairs”: 10,
“exchange”: “binance”
},
“filters”: {
“trailing”: {
“type”: “buyTrailing”,
“buyLevel”: 0.5,
“trailingRange”: 1
}
},
“schedule”: “* * * * *”,
“type”: “addPairs”,
“strategy”: “instantBuy”,
“enabled”: true,
“resume”: true,
“snapshots”: 60
},
Ticker history filters
Most ticker filters are also available as *History variant. These work in the same way as described above, but they use a different data set as input. Available history filters:
minPriceHistory
maxPriceHistory
maxVolumeRankHistory
minVolumeRankHistory
minPricePctChangeIntervalHistory
maxPricePctChangeIntervalHistory
minVolumePctChangeIntervalHistory
maxVolumePctChangeIntervalHistory
minVolume24hHistory
maxVolume24hHistory
minVolatilityPct24hHistory
maxVolatilityPct24hHistory
minSpreadPctHistory
maxSpreadPctHistory
minSlopePctIntervalHistory
maxSlopePctIntervalHistory
minStandardDevPctIntervalHistory
maxStandardDevPctIntervalHistory
bearishStandardDeviationChannelHistory
bullishStandardDeviationChannelHistory
History filters take one additional input, defining which history data should be used. the config for a history filter looks like:
“filter”: {
“type”: “minPriceHistory”,
“min”: 10,
“historySource”: 6
}
The historySource parameter in the example above means that it will use the price of the history entry with number 6. The oldest history entry has number 0.
How the history is built up is defined by the following parameters in the root level:
“history”: 7,
“historyInterval”: 15,
The example above would collect 7 history entries, with a minimum interval of 15 minutes.
New history entries are saved as follows:
When there is no history, the oldest ticker snapshot will be added as first history entry.
When there is at least one history entry, a new one is added when the time difference between the oldest ticker snapshot and the latest history entry is bigger than the time defined in historyInterval. The oldest ticker snapshot will be added as newest history entry. In case the maximum number of history entries is reached, the oldest history entry will get deleted once a new one gets added.
The config example below shows a job that filters for:
BTC pairs that currently ranks top10 for 24h volume
The 5 history entries have a slope of at least 1%
Pair must have ranked top10 24h volume in the oldest history entry
If oldest snapshot is > 60 minutes older than newest history entry,
it gets moved to history
Snapshots, 1m interval
[s] [s] [s] [s] [s] History entries, 60m interval |
[0] [1] [2] [3] [4] |
^———————–*
“addMoon”: {
“pairs”: {
“exclude”: “”,
“include”: “BTC-“,
“maxPairs”: 10,
“exchange”: “binance”
},
“filters”: {
“filter1”: {
“type”: “maxVolumeRank”,
“max”: 10
},
“filter2”: {
“type”: “minSlopePctIntervalHistory”,
“min”: 1,
“historySource”: 4
},
“filter3”: {
“type”: “maxVolumeRankHistory”,
“max”: 10,
“historySource”: 0
}
},
“schedule”: “* * * * * *”,
“type”: “addPairs”,
“strategy”: “moon”,
“snapshots”: 5,
“history”: 5,
“historyInterval”: 60,
“resume”: true
},
TIP
Both snapshots and history cause a relatively high load on I/O operations. Depending on your system, allowing for too many saved entries can negatively impact performance.
Pair state filters
State filters in AILidex use data from the internal ledger to filter pairs that have already cycled since the last (re)start. State data includes indicator values, balance data, candle data, and much more.
Type Description
exact Exact match between value and key in config and pair state; returns true when key and value match exactly.
biggerThan Value for key in pair state must be bigger than in config; returns true when emal in state is bigger than 0.25.
smallerThan Value for key in pair state must be smaller than in config; returns true when emal in state is smaller than 0.2.
compareBigger Compares values for two keys in state, values in config are irrelevant; returns true when emal is bigger than ema2 in state.
compareSmaller Compares values for two keys in state, values in config are irrelevant; returns true when emal is smaller than ema2 in state.
differenceBigger Compares values for two keys in state, values in config are irrelevant; returns true when percentage difference between emal and ema2 is bigger than delta (%).
differenceSmaller Compares values for two keys in state, values in config are irrelevant; returns true when percentage difference between emal and ema2 is smaller than delta (%).
Formula used in differenceBigger:
100 * ((ema2 – ema1) / ema1) > delta
Formula used in differenceSmaller:
100 * ((ema2 – ema1) / ema1) < delta
Please note that the ema1 and ema2 keys used in the formula examples can be replaced with any two keys. Just make sure you understand the positions of the keys to be compared in the configuration file because they matter.
Generic filters
Generic filters can be used with any job type, whether it primarily uses ticker or state filters. Here are the available filters:
Filter Type Description
variableExact Returns true when the variable value is exactly as defined.
variableNotExist Returns true when the variable key does not yet exist.
variableBiggerThan Returns true when the variable value is bigger than the target.
variableSmallerThan Returns true when the variable value is smaller than the target.
pairVariableSmallerThan Returns true when the pair-specific variable value is smaller than the target.
pairVariableBiggerThan Returns true when the pair-specific variable value is bigger than the target.
pairVariableExact Returns true when the pair-specific variable is exactly as defined. Can use an extra exchange input to check pair variables for another exchange.
strategyName Returns true when the strategy of an enabled pair is similar to the defined strategy name.
minTimeInConfig Returns true when the pair has been in the config for longer than a set number of minutes.
maxTimeInConfig Returns true when the pair has not been in the config for longer than a set number of minutes.
custom Allows you to use any custom JavaScript expression. The filter passes when the expression returns true.
Generic filter examples:
“Seconds since last order”: {
“type”: “custom”,
“target”: ” (function timeCheck(data){if(typeof data.orders===’undefined’){return false;} else if(typeof data.orders[0]===’undefined’){return false;} const lastOrderTime=data.orders[0].time;const secondsSinceLastOrder=(Date.now()-lastOrderTime)/1000;if(secondsSinceLastOrder<180){return true;}})(this)” }, “Price and EMA”: { “type”: “custom”, “target”: ” this.pair.ema1 > this.pair.Bid”
},
“time”: {
“type”: “minTimeInConfig”,
“min”: 60
},
“time”: {
“type”: “maxTimeInConfig”,
“max”: 90
} ,
“var”: {
“type”: “variableNotExist”,
“hedge”: “BTC”
},
“strat”: {
“type”: “strategyName”,
“name”: “moon”
},
User variables
AILidex allows you to define user variables for each job, which can be used for filtering in other jobs. You can use global variables and pair-specific variables to create more complex filter setups.
By using user variables, you can avoid repeating multiple filter conditions across multiple jobs and make job dependencies possible. For example, one job can monitor a specific condition and set a variable like liquidationStop: true when its conditions are met. Other jobs that depend on this liquidation stop can then set one filter looking for an exact match for liquidationStop: true, instead of repeating the same filters set in the job that monitors the distance between price and liquidation price.
A job sets a variable when at least one pair passes all filters for this job, and setVariable is defined in the job’s configuration. User variables can hold true/false values, number values, or strings, and the new value will overwrite the old one if it was previously set with a different value.
To set a global variable:
“setVariable”: {
“userVariable1”: true
},
To set pair specific variables, use a block like this:
“setPairVariable”: {
“awesomeVariable”: true,
“evenBetter”: true
},
All variables are written to a file and imported upon AILidex restarts, but file corruption can occur in certain situations. Therefore, it’s recommended to not fully depend on saved variables and run the jobs that set them relatively frequently. It’s a good practice to save absolutely critical data as a pair override in the config itself.
To read a variable, use the filter type variableExact. It can be used in all job types.
“filter”: {
“type”: “variableExact”,
“userVariable1”: true
}
The filter type for user variables is an exact match only, which returns true when userVariable1 has a value of true.
air variables can be read with a filter like this:
“pairVar”: {
“type”: “pairVariableExact”,
“awesomeVariable”: true
}
The same job that sets a variable can also reset it when no pairs pass all filters; this option is called resetVariable. It can contain one or more variables whose value can be filtered as an exact match, similar to setting a variable.
resetVariable looks like this:
“resetVariable”: {
“userVariable1”: true
}
To reset pair specific variables, use a block like this:
“resetPairVariable”: {
“awesomeVariable”: false,
“evenBetter”: false
}
TIP
It’s worth noting that variables are entirely optional, and no problem exists when no setVariable exists in a job.
Multiple filter sets
Instead of using a single set of filters, you can also add multiple sets of filters in a job.
Use this when you want to monitor for different conditions in a single job, if a pair passes all filters in any of the filter sets, changes are made.
Besides the obligatory first set of filters, you can add up to 9 more sets. named filters2 to filters10
Config example:
{
“example”: {
“pairs”: {
“exclude”: “”,
“include”: “”,
“maxPairs”: 500,
“noBag”: false,
“exchange”: “binance”
},
“filters”: {
“price”: {
“type”: “minPrice”,
“min”: 0.0000001
}
},
“filters2”: {
“minVolume24h”: {
“type”: “minVolume24h”,
“min”: 100
}
},
“schedule”: “*/30 * * * * *”,
“type”: “removePairs”,
“enabled”: true
}
}
Custom Code
Many elements in AutoConfig can be calculated at the time the job executes, this allows for completely dynamic scenarios for power users. Every valid javascript expression can be used.
You can use calculated values for the following elements in AutoConfig:
overrides
variables
pairVariables
maxPairs
target in filter type custom
To use an expression instead of a string or number, enter your expression as string with a leading blank space:
“validExpression”: ” 1 + 2″
When using custom expressions, be careful with internal data that’s available to you. It’s common to come across undefined data, but you can handle these errors by adding a filter that checks if the data exists or for example has a value greater than 0 before using it in an expression.
Use the following references to access internal data in your expressions:
Reference Content
this.config The complete AILidex config
this.pair All pair data the bot works with, the same as available in json state files
this.pairName String of the pair currently processing
this.variables All AutoConfig variables
this.pairVariables All AutoConfig pair variables
this.tickers All collected ticker snapshots, in case it’s ran in a job type that works with tickers.
this.userData User defined contents of acUserData.json in AILidex root folder.
Availability of pair specific data depends on the context where you’re trying to access it. For example a dynamic pair override value will have access to all pair specific data (because overrides are set for each pair, during a single job run), but a global variable won’t (because global variables are just set once per job run).
Examples of valid expressions
” this.pair.Bid * this.pair.quoteBalance”
// returns bag value in base currency
” (this.pair.Bid * this.pair.quoteBalance) > this.pair.whatstrat.MIN_VOLUME_TO_SELL ? true : false”
// returns true if bag is bigger than MVTS, false if not
” (function doStuff(data) {
if (data.pair.Bid > 0){
return true
}
else {
return false
}
})(this)” —> this example needs to be minified before it would work, as all code needs to be in a single line to not break JSON formatting.
” (function doStuff(data){if(data.pair.Bid>0){return true}else{return false}})(this)”
// minified example of the above
Example of a custom filter
“position bigger Than zero”: {
“type”: “custom”,
“target”: ” this.pair.quoteBalance * this.pair.Bid > parseFloat(this.pair.whatstrat.MIN_VOLUME_TO_SELL)”
},